Różnica między chmurą obliczeniową a Big Data

Zawartość
- Wykres porównania
- Definicja przetwarzania w chmurze
- Definicja dużych zbiorów danych
- Związek między chmurą obliczeniową a Big Data
- Wniosek
Przetwarzanie w chmurze działa w sposób skonsolidowany, a duże zbiory danych wchodzą w zakres przetwarzania w chmurze. Zasadnicza różnica między przetwarzaniem w chmurze a dużymi danymi polega na tym, że przetwarzanie w chmurze jest wykorzystywane do obsługi ogromnej pojemności pamięci (dużych danych) poprzez rozszerzenie zasobów obliczeniowych i pamięci. Z drugiej strony, duże zbiory danych to nic innego jak ogromna ilość nieuporządkowanych, zbędnych i hałaśliwych danych oraz informacji, z których należy wyciągnąć użyteczną wiedzę. Aby wykonać powyższą funkcję, technologia przetwarzania w chmurze zapewnia różne elastyczne i techniki radzenia sobie z ogromną ilością danych.
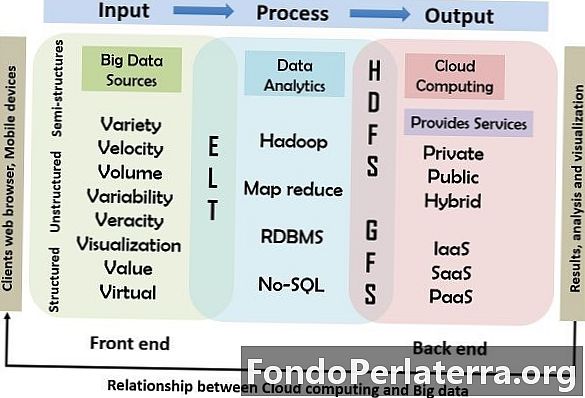
Obejmuje model wejściowy, przetwarzający i wyjściowy, który wyjaśniono poniżej; schemat szczegółowo ilustruje związek między przetwarzaniem w chmurze a dużymi danymi.
-
- Wykres porównania
- Definicja
- Kluczowe różnice
- Wniosek
Wykres porównania
| Podstawa do porównania | Chmura obliczeniowa | Big Data |
|---|---|---|
| Podstawowy | Usługi na żądanie są świadczone przy użyciu zintegrowanych zasobów i systemów komputerowych. | Obszerny zestaw ustrukturyzowanych, nieustrukturyzowanych, złożonych danych zabraniających pracy tradycyjnej techniki przetwarzania. |
| Cel, powód | Umożliwić przechowywanie i przetwarzanie danych na zdalnym serwerze oraz dostęp z dowolnego miejsca. | Organizacja dużej ilości danych i informacji do wyciągu ukryła cenną wiedzę. |
| Pracujący | przetwarzanie rozproszone służy do analizy danych i tworzenia bardziej przydatnych danych. | Internet jest wykorzystywany do świadczenia usług w chmurze. |
| Zalety | Niskie koszty utrzymania, scentralizowana platforma, możliwość tworzenia kopii zapasowych i odzyskiwania. | Ekonomiczna równoległość, skalowalna, solidna. |
| Wyzwania | Dostępność, transformacja, bezpieczeństwo, model opłat. | Różnorodność danych, przechowywanie danych, integracja danych, przetwarzanie danych i zarządzanie zasobami. |
Definicja przetwarzania w chmurze
Chmura obliczeniowa zapewnia zintegrowaną platformę usług do przechowywania i pobierania dowolnej ilości danych, w dowolnym czasie, z dowolnego miejsca na żądanie przy użyciu szybkiego Internetu. Chmura to szeroki zestaw serwerów naziemnych rozproszonych w Internecie do przechowywania, zarządzania i przetwarzania danych. Przetwarzanie w chmurze zostało opracowane w taki sposób, aby programiści mogli łatwo wdrożyć obliczenia na skalę internetową. Ewolucja Internetu stworzyła model przetwarzania w chmurze, ponieważ Internet jest podstawą przetwarzania w chmurze. Aby przetwarzanie w chmurze działało efektywnie, potrzebujemy szybkiego połączenia z Internetem. Oferuje elastyczne środowisko, w którym pojemność i możliwości można dynamicznie dodawać i wykorzystywać zgodnie ze strategią pay per use.
Przetwarzanie w chmurze ma pewne podstawowe właściwości, takie jak pula zasobów, samoobsługa na żądanie, dostęp do szerokiej sieci, usługa mierzona i szybka elastyczność. Istnieją cztery rodzaje chmury - publiczna, prywatna, hybrydowa i społecznościowa.
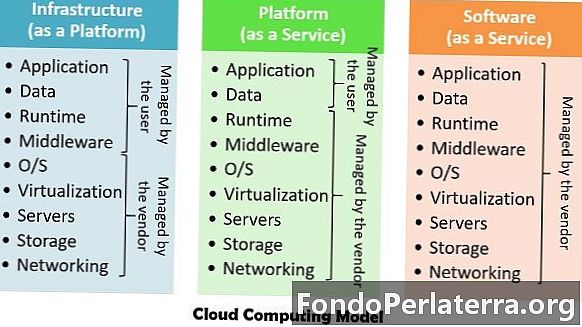
Istnieją w zasadzie trzy modele przetwarzania w chmurze - platforma jako usługa (Paas), infrastruktura jako usługa (Iaas), oprogramowanie jako usługa (Saas), która korzysta zarówno ze sprzętu, jak i usług programowych.
- infrastruktura jako usługa - Ta usługa służy do dostarczania infrastruktury, która obejmuje moc przetwarzania pamięci i maszyny wirtualne. Realizuje wirtualizację zasobów na podstawie umowy o gwarantowanym poziomie usług (SLA).
- Platforma jako usługa - Występuje powyżej warstwy IaaS, która zapewnia środowisko programistyczne i wykonawcze, aby umożliwić użytkownikom wdrażanie aplikacji w chmurze.
- Oprogramowanie jako usługa - Dostarcza aplikacje do klienta, które działają bezpośrednio na dostawcy chmury.
Definicja dużych zbiorów danych
Dane zmieniają się w duże dane wraz ze wzrostem objętości, różnorodności, prędkości wykraczającym poza możliwości systemów informatycznych, co z kolei powoduje trudności w przechowywaniu, analizie i przetwarzaniu danych. Niektóre organizacje opracowały sprzęt i wiedzę specjalistyczną, aby poradzić sobie z tego rodzaju ogromną ilością ustrukturyzowanych danych, ale wykładniczo rosnące objętości i szybki przepływ danych przestają być zdolne do moje i szybkie generowanie inteligencji, którą można zastosować. Te obszerne dane nie mogą być przechowywane w zwykłych urządzeniach i rozproszone w środowisku rozproszonym. Obliczanie dużych zbiorów danych to początkowa koncepcja nauka danych który koncentruje się na wielowymiarowej eksploracji informacji w celu odkryć naukowych i analiz biznesowych dotyczących infrastruktury na dużą skalę.
Podstawowymi wymiarami dużych zbiorów danych są objętość, prędkość, różnorodność i prawdziwość, które są również wspomniane powyżej, później powstają dwa kolejne wymiary, które są zmiennością i wartością.
- Tom - Oznacza rosnący rozmiar danych, który jest już problematyczny w przetwarzaniu i przechowywaniu.
- Prędkość - Jest to przypadek, w którym dane są przechwytywane i prędkość przepływu danych.
- Różnorodność - Dane nie zawsze są prezentowane w jednej formie, istnieją różne formy danych, na przykład - audio, obraz i wideo.
- Prawdziwość - Określa się to jako wiarygodność danych.
- Zmienność - Opisuje wiarygodność, złożoność i niespójności powstałe w przypadku dużych zbiorów danych.
- Wartość - Oryginalna forma treści może nie być zbyt użyteczna i produktywna, dlatego dane są analizowane i odkrywane są dane o wysokiej wartości.
- Przetwarzanie w chmurze to usługa obliczeniowa świadczona na żądanie przy użyciu zasobów obliczeniowych rozproszonych w Internecie. Z drugiej strony, duże dane to ogromny zestaw danych komputerowych, w tym danych ustrukturyzowanych, nieustrukturyzowanych, częściowo ustrukturyzowanych, których nie można przetworzyć tradycyjnymi algorytmami i technikami.
- Przetwarzanie w chmurze zapewnia użytkownikom platformę do korzystania z usług, takich jak Saas, Paas i Iaas, na żądanie, a także pobiera opłaty za usługę zgodnie z użytkowaniem. Natomiast głównym celem dużych zbiorów danych jest wydobycie ukrytej wiedzy i wzorców z ogromnego zbioru danych.
- Szybkie łącze internetowe jest niezbędnym wymogiem dla przetwarzania w chmurze. W przeciwieństwie do tego, duże zbiory danych wykorzystują przetwarzanie rozproszone w celu analizy i eksploracji danych.
Związek między chmurą obliczeniową a Big Data
Poniższy schemat ilustruje związek i działanie przetwarzania w chmurze z dużymi danymi. W tym modelu podstawowy model przetwarzania danych wejściowych, przetwarzania i danych wyjściowych jest wykorzystywany jako odniesienie, w którym duże dane są wstawiane do systemu za pomocą urządzeń wejściowych, takich jak mysz, klawiatura, telefony komórkowe i inne inteligentne urządzenia. Drugi etap przetwarzania obejmuje narzędzia i techniki wykorzystywane przez chmurę do świadczenia usług. W końcu wynik przetwarzania jest dostarczany użytkownikom.
Wniosek
Technologia przetwarzania w chmurze zapewnia odpowiednią i zgodną z ramami dla dużych zbiorów danych łatwość użycia, dostęp do zasobów, niski koszt wykorzystania zasobów podaży i popytu, a także minimalizuje użycie solidnego sprzętu wykorzystywanego do obsługi dużych zbiorów danych. Zarówno chmura, jak i duże zbiory danych kładą nacisk na zwiększenie wartości firmy przy jednoczesnym obniżeniu kosztów inwestycji.





